Od kilku ładnych tygodni o desktopowych Comet Lake wiemy już w zasadzie wszystko, począwszy od ich specyfikacji technicznej a na braku wstecznej kompatybilności z obecnymi płytami głównymi kończąc. W największym skrócie po raz kolejny mamy do czynienia ze zmodyfikowaną architekturą Skylake produkowaną w litografii 14nm, która niestety tym razem nie przynosi zbyt wielu nowości. W zasadzie to naprawdę ciężko znaleźć jakikolwiek argument, który przemawiałby nad wyższością CPU Gen 10 nad obecnie sprzedawaną Gen 9. Mimo to nadal czekamy na ich premierę, a w tzw. międzyczasie do sieci trafiają kolejne nieoficjalne testy wydajności układów Comet Lake.
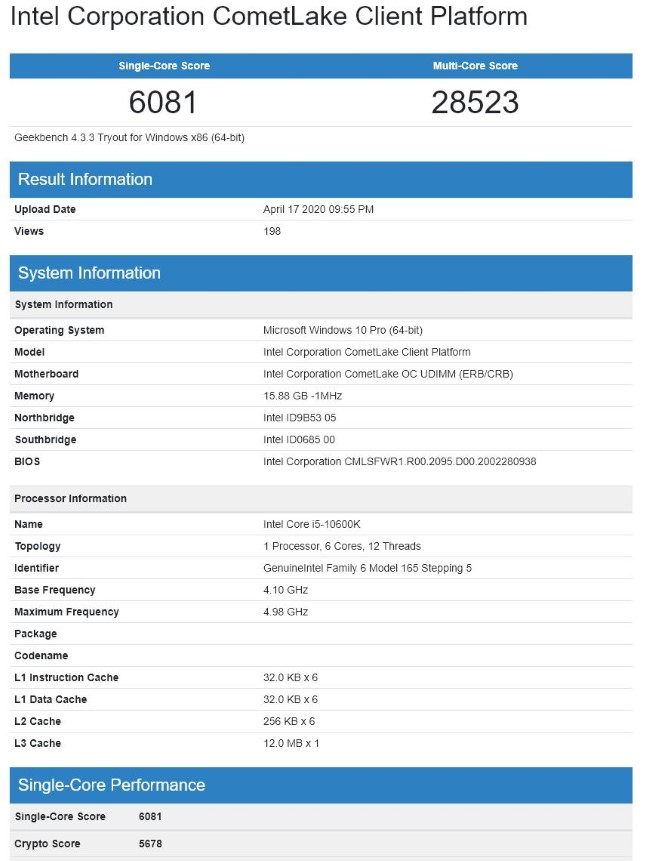
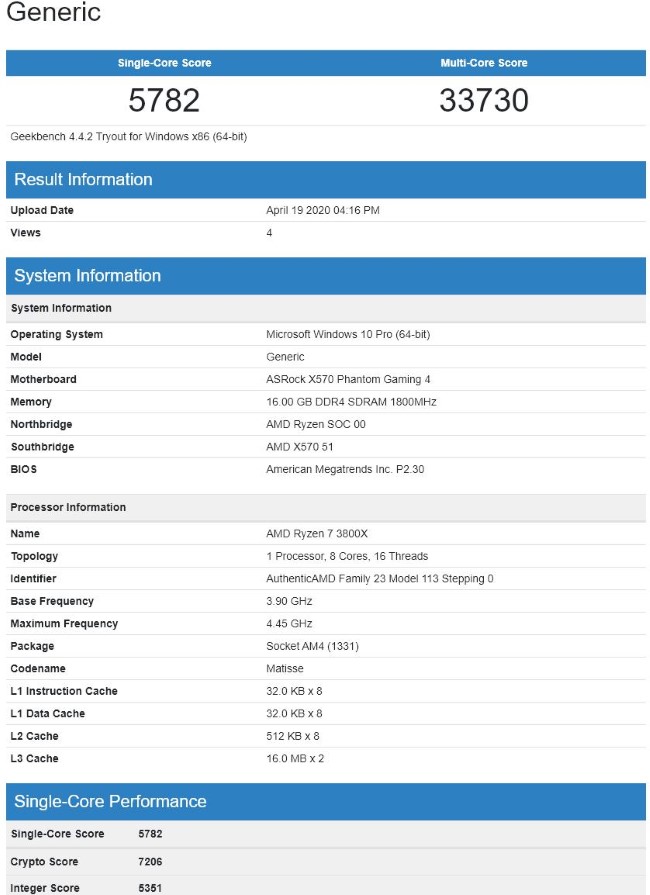
Najnowsze wykonano w Geekbenchu z wykorzystaniem 8-rdzeniowego i 16-wątkowego Core i7-10700K i 6-rdzeniowego oraz 12-wątkowego Core i5-10600K. Pierwszy z chipów pracując z zegarem dochodzącym do 5,1GHz (w TURBO) uzyskał wynik 34 133pkt w teście wielordzeniowym i 5 989pkt w jednordzeniowym, a w przypadku i5-10600K z zegarem do 4,8GHz było to odpowiednio 28 523pkt oraz 6 081pkt.
Innymi słowy mamy do czynienia z wynikiem na poziomie odpowiednio Ryzenów 7 3800X oraz 3600X jeśli chodzi o testy wielordzeniowe, natomiast w grach, gdzie liczy się przede wszystkim mocny wątek Intel będzie zapewne górą. Tyle tylko, że kosztem wyższego zużycia energii i dzięki wyższemu zegarowi, a nie lepszemu IPC.
Osobną kwestią są ceny płyt z chipsetem Z490, które ponoć będą się zaczynać od około 200 Euro za najtańszy model i będą szybować aż do granicy 1000 Euro. Słowem tanio nie będzie.
K O M E N T A R Z E
"W zasadzie to naprawdę ciężko znaleźć jakikolwiek argument..." (autor: Qjanusz | data: 20/04/20 | godz.: 20:49) Argumentem będzie ekskluzywna podstawka LGA1200, której właściciel może być pewny, że żaden power user nie miał wcześniej do czynienia z tak gorącym(!) towarem.
O cenach za Z490 to już legendy w necie krążą.
Ale z drugiej strony trzeba oddać inżynierom Intela, co do nich należy. Wykrzesać z 14nm tyle, ile AMD wyciska z 7nm, to wyczyn nie lada.
single-core (autor: Conan Barbarian | data: 20/04/20 | godz.: 22:51) Niech mnie ktoś oświeci z czego wynika lepszy rezultat i5-10600K od i7-10700K w single-core?
@up (autor: Wedelek | data: 21/04/20 | godz.: 07:06) Najprawdopodobniej jest to pochodna większej ilości rdzeni. Każdy z nich wytwarza określone ciepło (nawet w trybie IDLE) i suma sumarum CPU z większą ich ilością grzeje się szybciej, przez co TURBO działa z niższymi zegarami (średnio).
@Qjanusz (autor: Marek1981 | data: 21/04/20 | godz.: 08:22) "Wykrzesać z 14nm tyle, ile AMD wyciska z 7nm, to wyczyn nie lada" 1) to tylko cyferki oderwane od rzeczywistości. 2) Intel dopracowuje ten proces ponad 5lat, a AMD wrzuciło produkt po krótkich testach.
@1. (autor: pandy | data: 21/04/20 | godz.: 11:30) To nie problem wykrzesywania a problem powierzchni struktury, tego ile można struktur wsadzić na wafel i ile w efekcie końcowym zarobić pieniędzy. AMD może mieć większy zysk przy niższej cenie. Osiągi mają tu znaczenie lekko wtórne dopóki kreci się biznes.
@2. (autor: Mariosti | data: 21/04/20 | godz.: 13:10) Zapewne może być to też kwestia interconnectów rdzeni.
7 lat 4 rdzeniowych inteli słynęło z niskich opóźnień w komunikacji między rdzeniami, cache i ramem i wynikało to z szybkiego w takim scenariuszu ringbusa.
Modele serwerowe miały w tym celu już 2 ringbusy i opóźnienia od razu miały wyraźnie wyższe i niekonsystentne między rdzeniami.
Obecnie szczerze mówiąc nie wiem jak to intel rozwiązał zaczynając od i7-8700k przechodząc na 6 rdzeni, jak na 8 a jak teraz na 10 rdzeni.
Zapewne wiele by to wyjaśniło, ale przy premierach nie widziałem aby się tym chwalili...
AMD korzysta z zupełnie innego rozwiązania, bardzo skalowalnego, ale nie mogącego zejść do tak niskich opóźnień jak u intela przy niskiej liczbie rdzeni, co jak widać jednak nie daje już takiej przewagi jak kiedy, a z kolei daje to straszną stratę w stosunku do AMD w przypadku stosowania dużej liczby rdzeni.
@6. (autor: pwil2 | data: 22/04/20 | godz.: 16:25) Pewnie podnoszą taktowania szyny. Serwerowe z małą ilością rdzeni miały tylko jeden ring.
Rozwiązanie z CCXami się tak dobrze skaluje, bo każda 2-4 rdzeni ma niezależną przepustowość do swojego lokalnego L3 cache. Im więcej CCXów, tym więcej przepustowości.
Większe opóźnienia zmniejszają przepustowość wątku, ale już niekoniecznie całego rdzenia składającego się z 2 wątków. Gdy jeden rdzeń czeka na dane, drugi ma do dyspozycji więcej zasobów. W efekcie Ryzeny bardziej zyskują na wykorzystaniu wielowątkowości.
D O D A J K O M E N T A R Z
Aby dodawać komentarze, należy się wpierw zarejestrować, ewentualnie jeśli posiadasz już swoje konto, należy się zalogować.

")