AMD ZEN 2 : szczegóły nowej architektury
Autor: Zbyszek | Data: 14/06/19
| |
|
Architektura X86
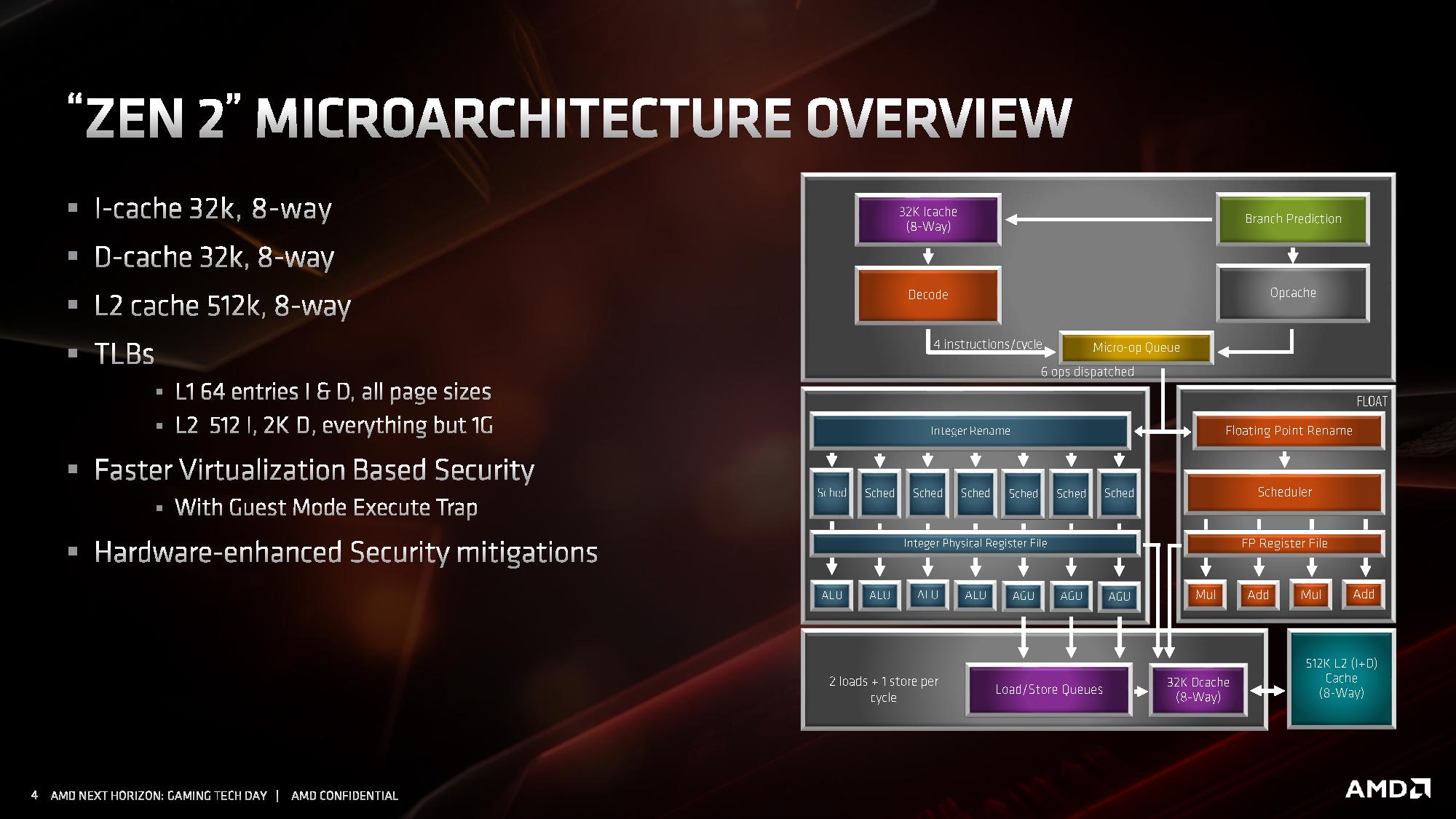
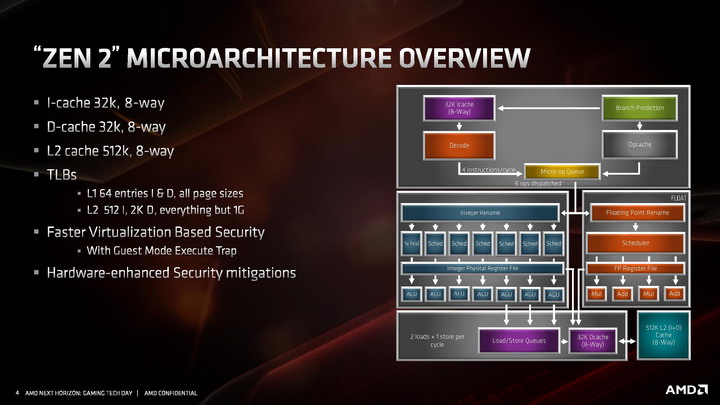
Przechodząc do bardziej ciekawych szczegółów, zaglądamy wgłąb modułu CCX, analizując budowę pojedynczego rdzenia z architekturą ZEN 2. Architektura ZEN 2, względem dotychczasowej ZEN / ZEN+, wprowadza usprawnioną część stałoprzecinkową i znacznie rozbudową jednostkę zmiennoprzecinkową. Towarzyszy temu znacznie usprawniony Front End, czyli część zasilająca potoki i jednostki wykonawcze w instrukcje.

(kliknij, aby powiększyć)
(kliknij, aby powiększyć)
Front-End
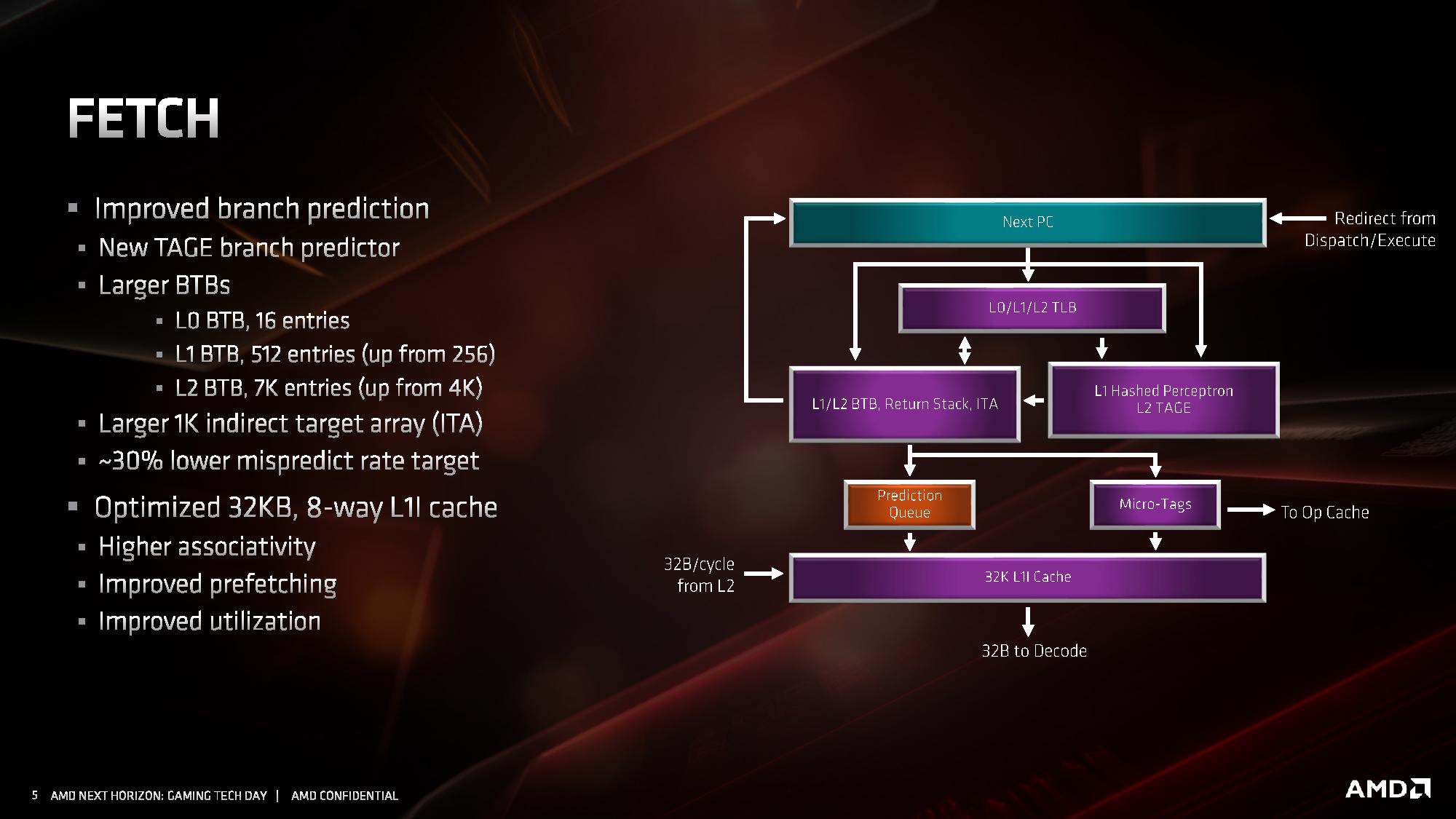
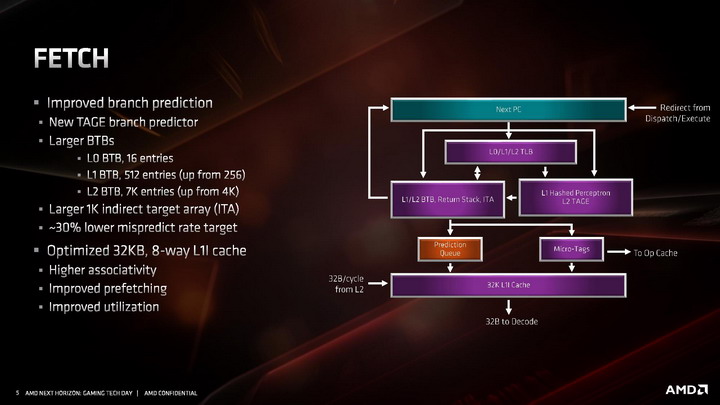
W części odpowiadającej za wczytywanie instrukcji, udoskonalono system przewidywania rozgałęzień. Usprawniono algorytmy odpowiadające za przewidywanie skoków, a także znacznie powiększono bufory predykcyjne rozgałęzień (BTB) dla instrukcji z pamięci L1 i L2. Pojawiła się także nowa dodatkowa logika przewidująca rozgałęzienia w innych sposób, nazywana TAGE branch predictor, bazująca w większym stopniu na analizie tego, czy poprzednio zachowanie instrukcji zostało przewidziane prawidłowo, czy nie, a następnie tagowaniu skutecznych przewidywań. Sumarycznie wszystkie zmiany wpłynęły na około 30 procentowy spadek liczby nietrafionych predykcji.
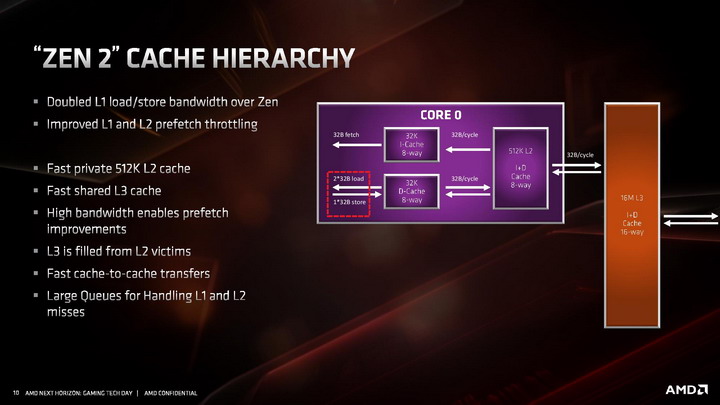
Przebudowana została pamięć podręczna 1. poziomu dla instrukcji, która ma teraz pojemność 32 KB, o połowię mniejszą niż w pierwszej generacji architektury ZEN, ale jej budowa została zmieniona z 4-kanałowej na 8-kanałową, przez co pamięć jest sprawniejsza, ma wyższą przepustowość i efektywniej wykorzystuje swoją pojemność . Uzyskane w ten sposób tranzystory pozwoliły natomiast dwukrotnie powiększyć pamięć podręczną L0, przechowującą zdekodowane mikroinstrukcje. W architekturze ZEN 2 mieści ona 4096 ostatnich instrukcji przetworzonych przez dekoder rozkazów, zamiast 2048 jak w architekturach ZEN / ZEN+. Dla porównania analogiczna pamięć w architekturze Skylake mieści 1536 instrukcji, a w architekturze Sunny Cove mieści 2560 instrukcji.
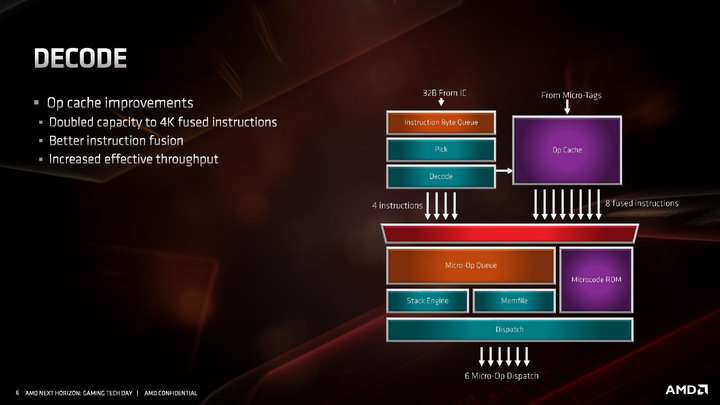
Kolejne z modyfikacji poczynionych w architekturze ZEN 2 objęły dekoder rozkazów, czyli jednostki konwertujące archaiczne instrukcje x86 w mikro-instrukcje wewnętrzne procesora. Dekoder rozkazów w ZEN 2 nadal jest 4-drożny, ale poczyniono modyfikacje zwiększające jego przepustowość oraz usprawniono funkcję odpowiadające za fuzję instrukcji, czyli łączenie ich w paczki i wspólne dekodowanie w jednym dekoderze. Nowy algorytm jest w stanie połączyć do 8 instrukcji x86 w jedną. Kolejna modyfikacja dotyczy instrukcji AVX2, które są teraz przetwarzane w jednym takcie zegara przez jedną jednostkę dekodującą, bez potrzeby rozdzielania ich na dwie odrębne 128-bitowe instrukcje - co zmniejsza zajętość pozostałych trzech dekoderów.
Zmodyfikowany dekoder rozkazów czerpie też korzyści z dwukrotnie powiększonej pamięci podręcznej L0, przechowującej zdekodowane mikro-instrukcje. Jej większa pojemność sprawia, że już raz przetworzone instrukcje rzadziej muszą być dekodowane ponownie, co pozwala dekoderowi zająć się innymi rozkazami i dostarczyć więcej instrukcji do potoków wykonawczych procesora.
Część stałoprzecinkowa i zmiennoprzecinkowa
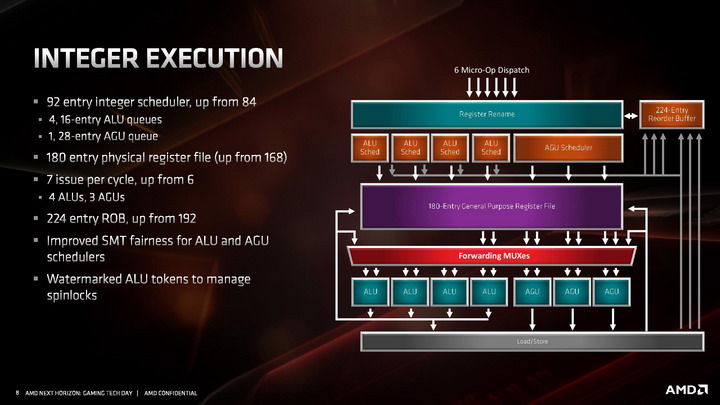
W części stałoprzecinkowej AMD zdecydowało się zwiększyć liczbę potoków wykonawczych z 6 do 7, dodając dodatkowy potok z jednostką AGU. Sumarycznie architektura ZEN 2 zawiera więc 4 jednostki ALU i 3 jednostki AGU. To oczywiście nie wszystkie ze zmian. Reorder buffer, czyli bufor odpowiadający za przekolejkowanie instrukcji przed ich wykonaniem został powiększony z 192 do 224 pozycji. Usprawniono także Scheduler, odpowiadający za przydzielanie jednostkom wykonawczym instrukcji do wykonania. Jednostki ALU posiadają teraz 16 wejściowe Schedulery, zamiast 14-wejściowych, a jednostki AGU otrzymały jeden zunifikowany 28-wejściowy Scheduler. Powiększono także zestaw fizycznych rejestrów, aby zmniejszyć ryzyko potencjalnego wstrzymywania wykonywania operacji z powodu tymczasowego braku wolnego rejestru.
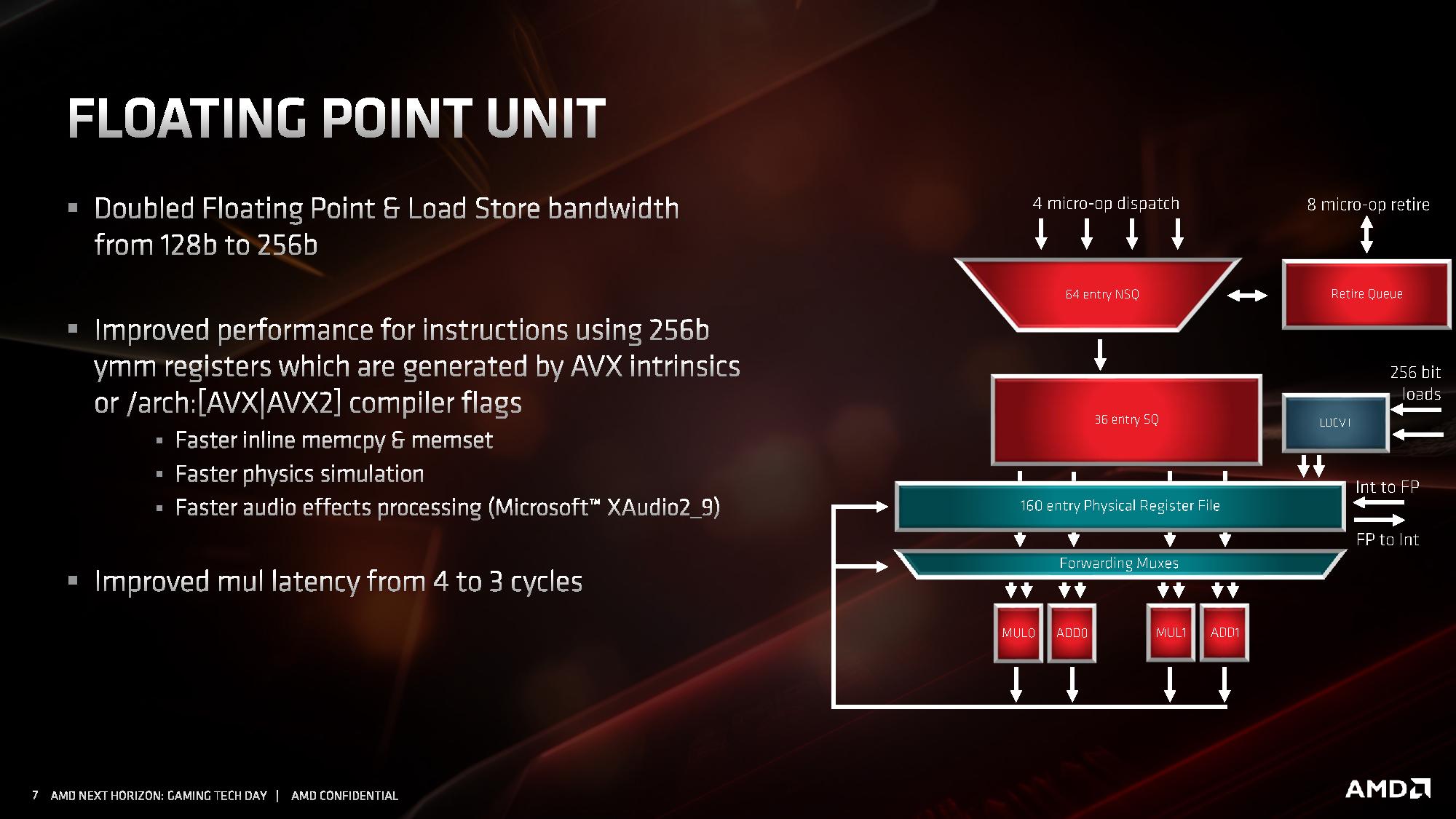
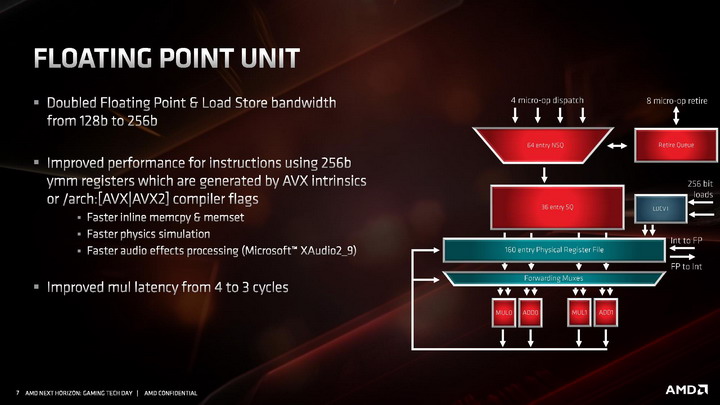
Jednostka zmiennoprzecinkowa w architekturze ZEN 2 zachowała czteropotokową budowę, ale każda z czterech dostępnych jednostek wykonawczych jest teraz natywnie 256-bitowa, co pozwala na obsługę instrukcji AVX2 bez potrzeby dzielenia ich na dwie 128-bitowe instrukcje. Skutuje to oczywiście dwukrotnym wzrostem wydajności zmiennoprzecinkowej podczas pracy z 256-bitowymi instrukcjami. Ale to nie wszystko. Oprócz tego przyspieszono wykonywanie operacji mnożenia, której wykonanie zajmuje teraz 3 cykle zegara zamiast 4 cykli. Usprawnienie to ma dać wyższą wydajność zmiennoprzecinkową niezależnie od tego, czy procesor pracuje z instrukcjami AVX2, czy też starszymi rozkazami AVX i SSE.
Część odpowiadająca za ładowanie i odbieranie danych
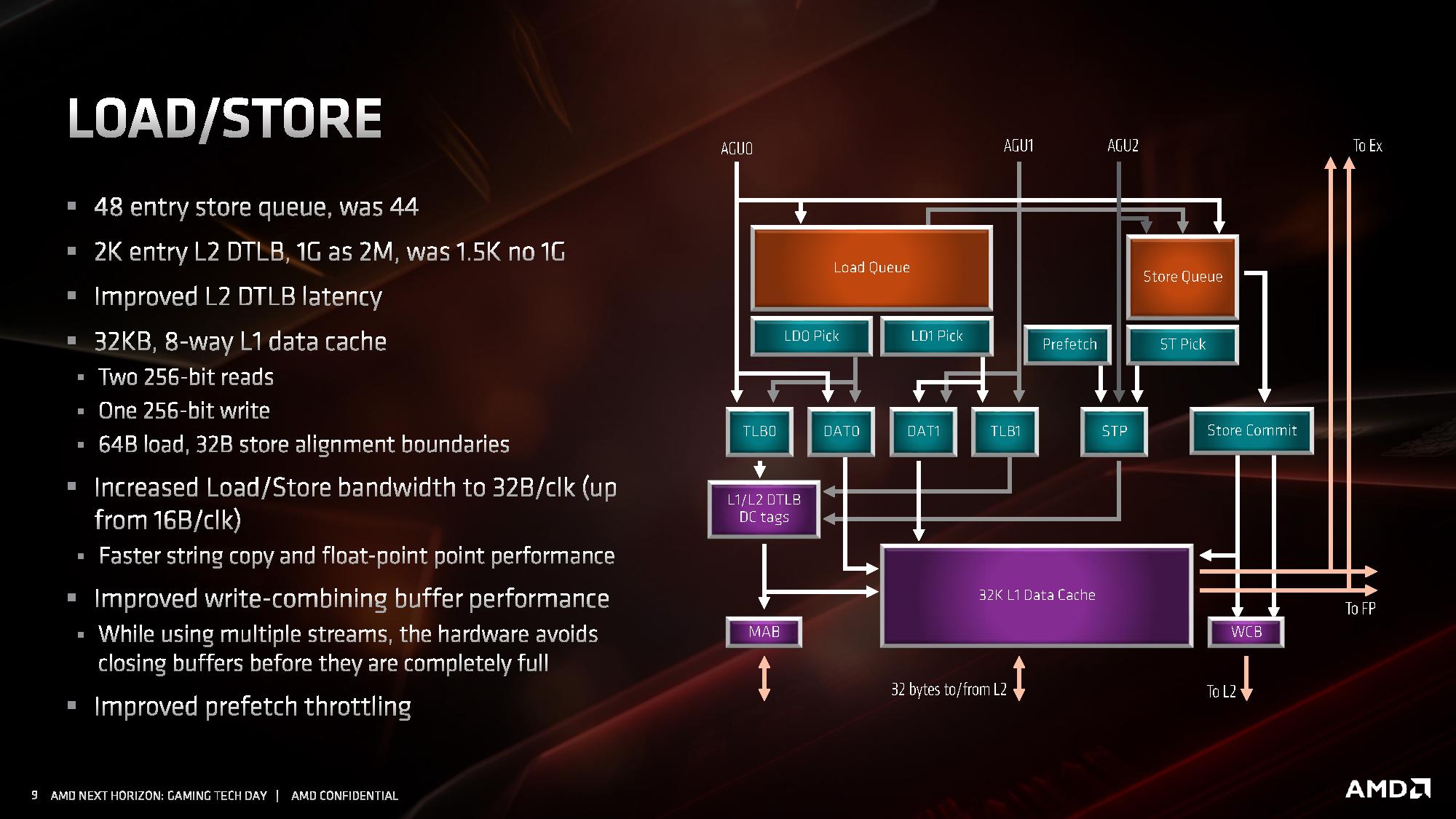
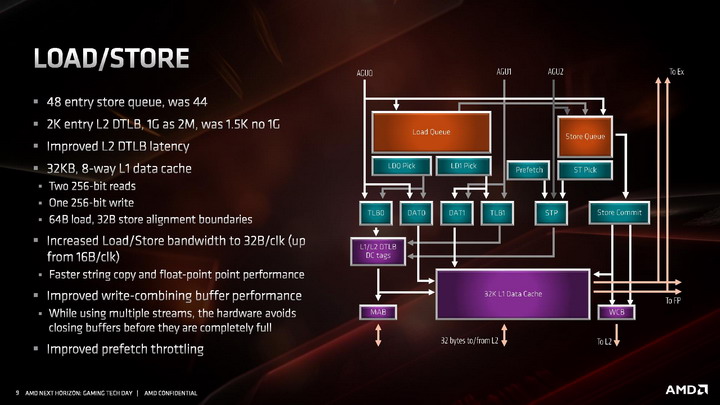
Kolejne z ulepszeń objęły część architektury odpowiadającą za ładowanie i odbieranie danych do wykonujących na nich instrukcje jednostek wykonawczych. Zmiany wprowadzone w tej części objęły dwukrotny wzrost przepustowości, wymagany do tego, aby 256-bitowe jednostki zmiennoprzecinkowe mogły zostać obsłużone danymi. W architekturze ZEN 2 część load / store jest w stanie obsłużyć natywnie 32 bajty danych, zamiast 16 bajtów jak dotychczas.
Poza tym wprowadzono także szereg drobnych ulepszeń skutkujących wzrostem wydajności ładowania i zapisu danych w każdym scenariuszu, nie tylko gdy wykonywane są instrukcje AVX 2. W tym celu dwukrotnie zwiększono przepustowość pamięci podręcznej L1 dla danych, powiększono kolejkę zapisu z 44 do 48 pozycji, ulepszono mechanizm TLB dla pamięci L2, powiększono wydajność buforów oraz zmniejszono ich opóźnienia, zmniejszając ryzyko tzw. throttlingu, czyli sytuacji, w której dane na których mają operować instrukcje nie zostaną dostarczone do jednostek wykonawczych na czas.
(kliknij, aby powiększyć)
(kliknij, aby powiększyć)
(kliknij, aby powiększyć)
(kliknij, aby powiększyć)
(kliknij, aby powiększyć)
(kliknij, aby powiększyć)
|